想让你的电脑瞬间变身智能助手吗?DeepSeek R1模型帮你轻松实现!这篇文章将带你一步步部署这个强大的AI模型到本地,让你亲身体验它的推理能力。无论是windows、MacOS还是Linux用户,只需几分钟,你就能在自己的设备上运行DeepSeek R1,享受流畅的AI互动。
1.我们需要下载并安装Ollama客户端,这一步骤简单快捷,官网直接访问,国内用户也能顺畅安装。接着,通过几行简单的命令,你就可以让DeepSeek R1模型在你的电脑上跑起来。显卡要求不高,即使是老款显卡也能胜任,只要显存足够就行。想知道具体步骤和更多高级特性?快跟着我们一起探索吧!
步骤一:下载安装Ollama软件
首先,访问Ollama官网,下载并安装Ollama客户端,支持Windows、MacOS和Linux系统。对于国内用户,官网可以直接访问,安装过程也十分简便。
步骤二:运行命令部署DeepSeek R1模型
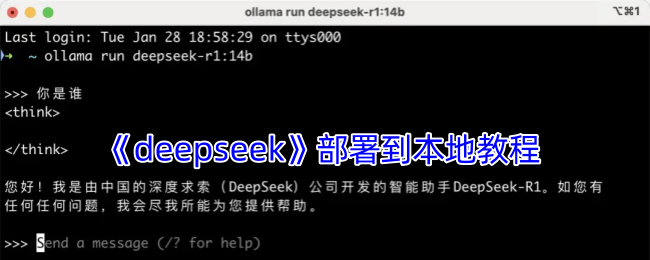
安装好Ollama后,打开命令行窗口,输入以下命令:
bash复制编辑ollama run deepseek-r1:7b
此命令会自动下载并部署DeepSeek R1的7B模型。
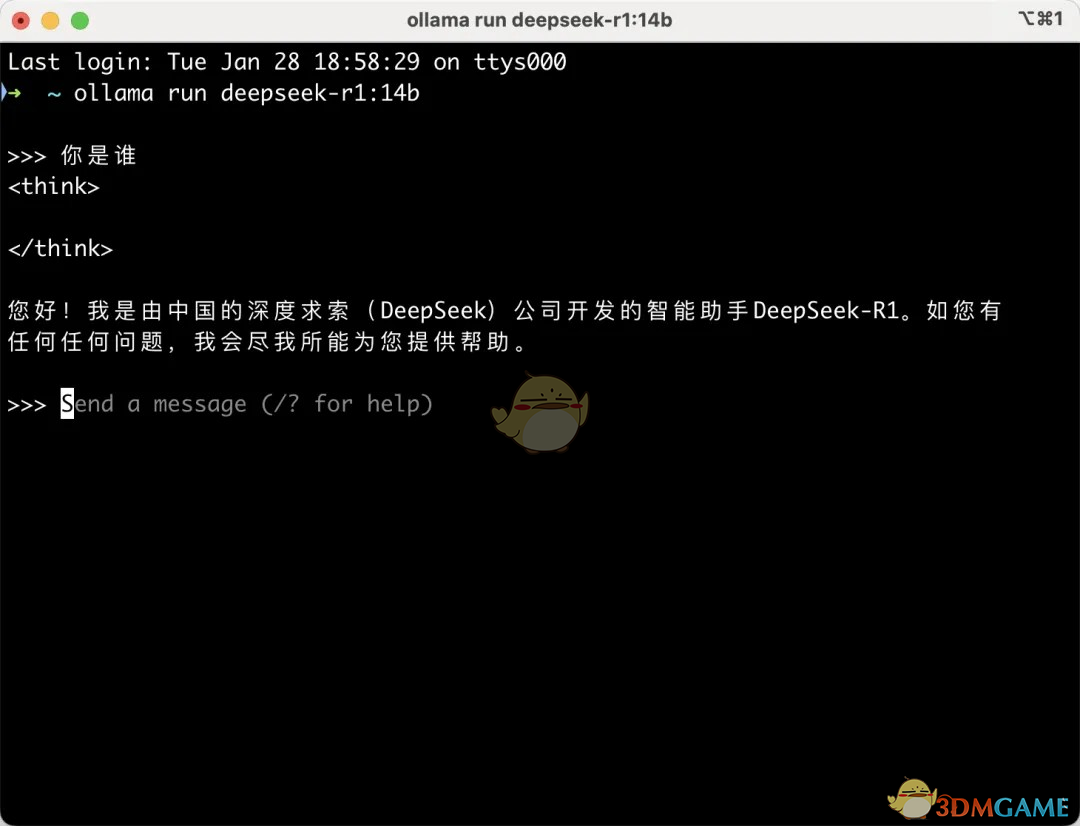
部署成功后,你就可以体验DeepSeek R1模型强大的推理能力了。
如果你希望尝试更高性能的模型,接着看下文的高级特性部分。
高级特性
1、确定电脑是否能运行某个参数量的模型
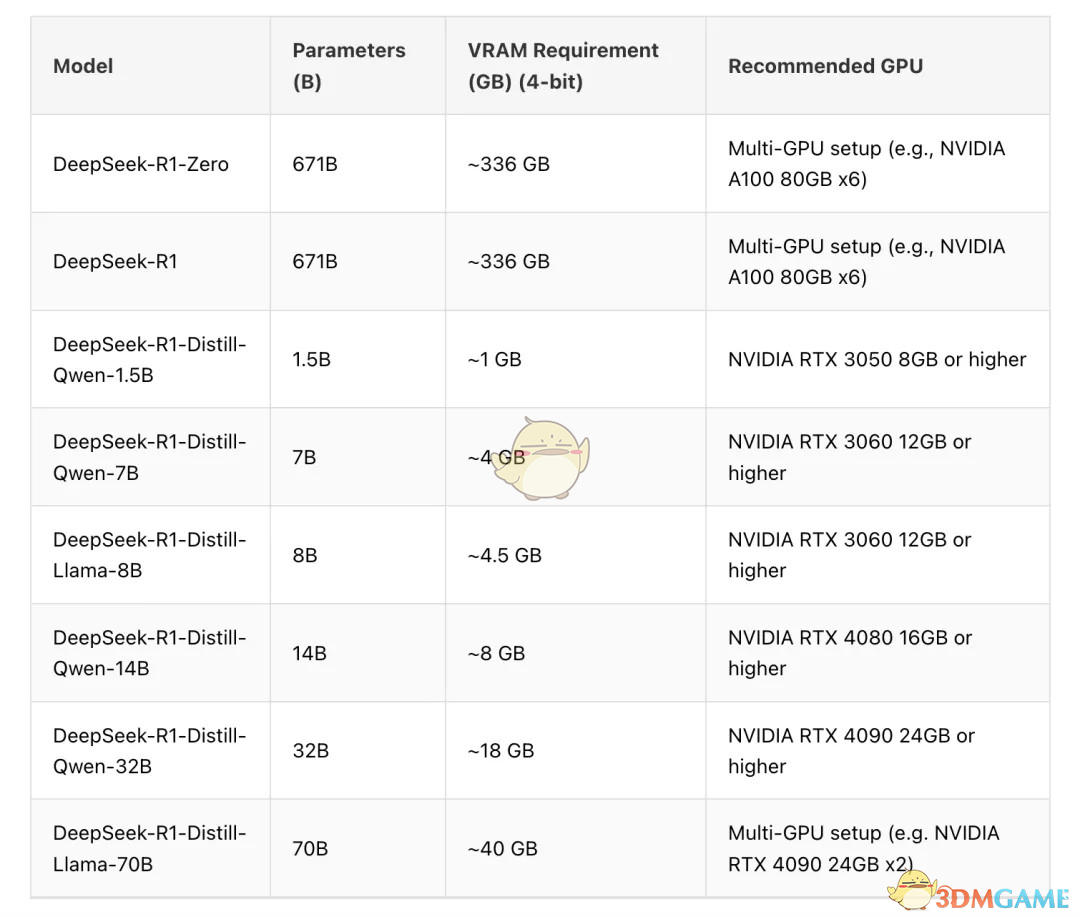
要确认你的电脑是否能够运行DeepSeek R1模型,关键是看显卡的显存大小。
显卡性能要求相对较低,即使是像 1080、2080 这样的老显卡,也能运行得相当流畅。
只要显存够用,就可以顺利运行模型。
这里是显卡显存要求的参考表:
显卡要求详情
2、运行不同参数量的模型
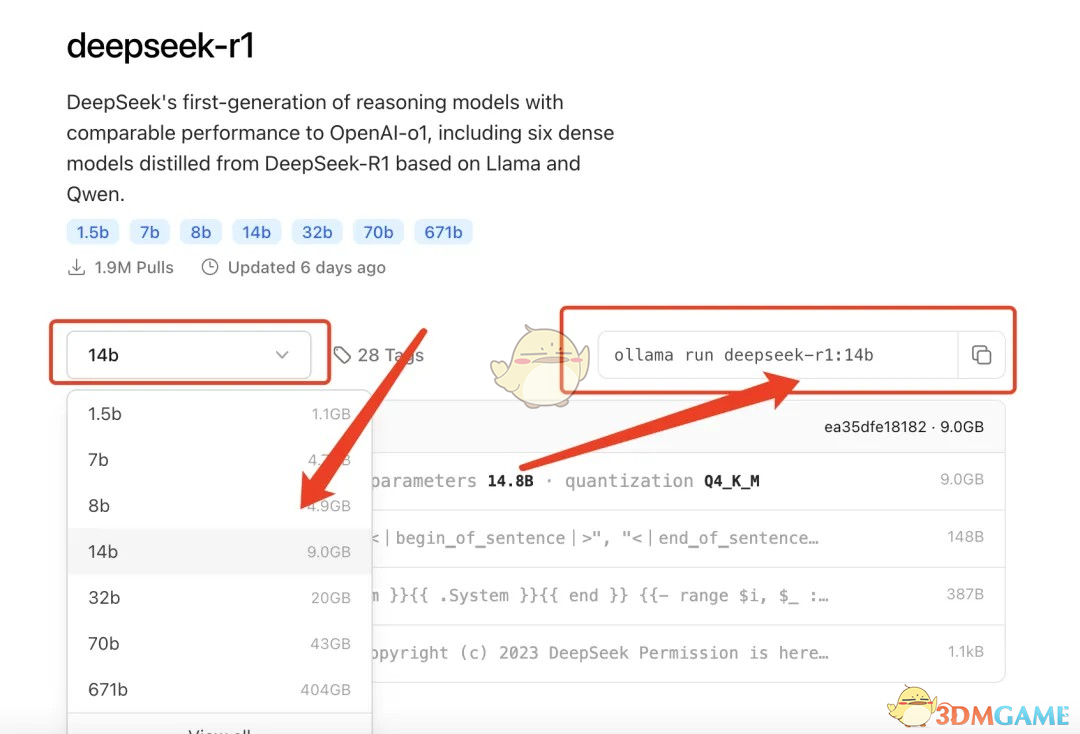
了解自己显卡的显存后,你可以选择更适合的模型。
通过访问Ollama官网并搜索DeepSeek,你可以找到R1系列的不同参数模型。
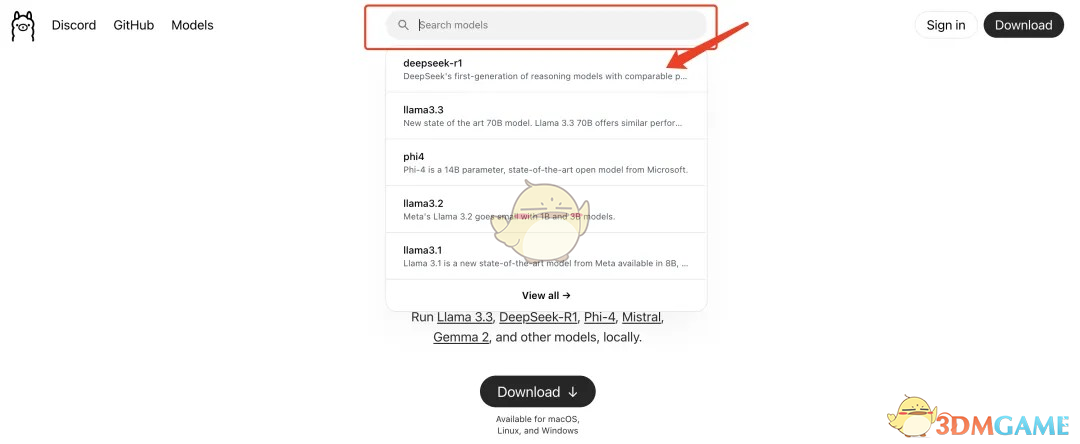
模型的参数越大,效果通常越好。
找到你需要的模型后,复制右侧提供的命令,在命令行中运行即可。
3、运行命令客户端
你可以通过以下终端程序运行命令:
Windows: CMD 或 PowerShell
MacOS: iTerm 或 Terminal
Linux: 任意终端

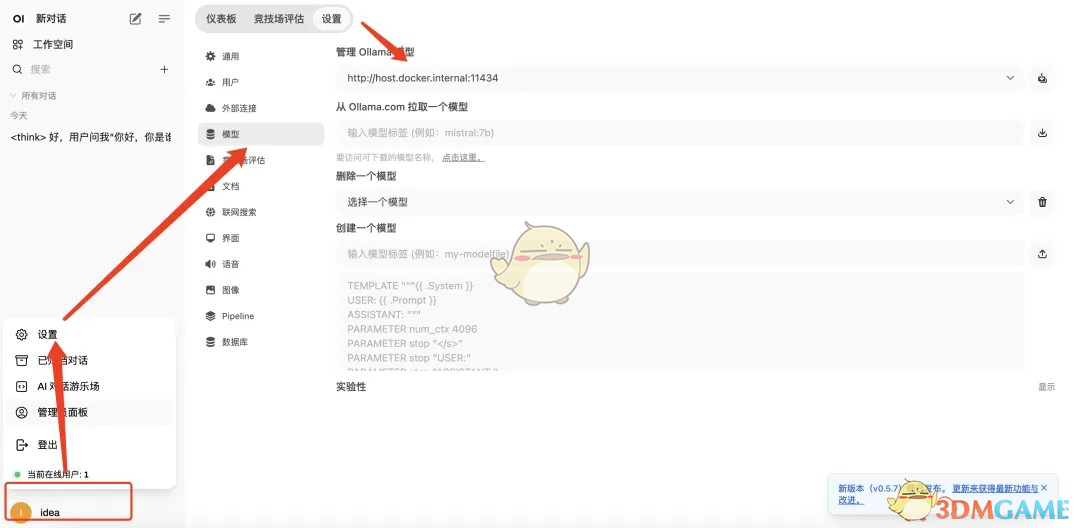
4、使用美观的客户端与模型互动
部署好DeepSeek R1模型后,你可以选择一个漂亮的客户端来与模型进行对话。
一个很棒的开源项目是Open Web UI,它支持与Ollama 部署的模型互动。
你只需填入本地服务的地址localhost:11434即可(默认端口是 11431)。
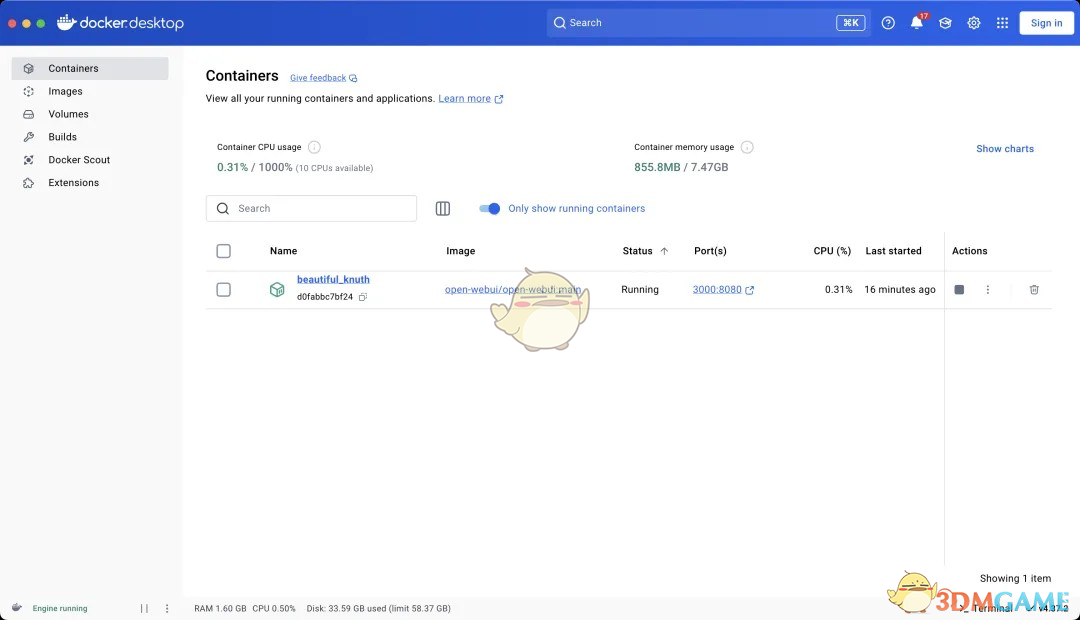
如果你熟悉Docker,还可以通过Docker来运行这个客户端。
另外,如果你需要其他更漂亮的客户端,可以试试Lobe-Chat,它也是开源的,并且非常简洁易用。